
Los modelos Cogito V2 tienen una autoinición
¿Quieres visiones más inteligentes de tu bandeja de entrada? Suscríbase a nuestros boletines semanales para obtener lo que se refiere solo a la IA de las instituciones, los líderes de datos y seguridad. Suscríbete ahora
Deep Cogito, Startup de investigación de IA, ha publicado su San Francisco con base en el mercado, que fue fundada por el antiguo mercado, cuatro nuevos LLMS Modelos de idiomas grandes (LLM) Esto está tratando de ver con algunos: aprender a pensar de manera más efectiva con el tiempo y mejorarlo por su cuenta.
Los modelos, que se han lanzado como parte de la familia Cogito V2, varían de 70 mil millones a 671 mil millones de maestros y están disponibles para desarrolladores e instituciones de inteligencia artificial para su uso a la luz de una combinación de condiciones de licencias limitadas y completamente abiertas. Incluye:
- Cogite V2-70B (denso)
- Cogito V2-109B (expertos mixtos)
- Cogito V2-405B (denso)
- Cogito V2-671B (mee)
Los modelos densos son adecuados para cada una de las diferentes necesidades. Activando modelos variables 70B y 405b gruesos Todos los parámetros en cada pase, lo que los hace más predecibles y más fáciles de publicar a través de una amplia gama de dispositivos.
Es ideal para aplicaciones de baja representación, control y entornos de capacidad limitada en la unidad de procesamiento de gráficos. Los modelos MEE, como las versiones 109B y 671B, usan un mecanismo de guía disperso para activar solo unos pocos «expertos» de sub -networks especializados al mismo tiempo, lo que permite que los tamaños de modelos totales generales mucho más grandes sin un aumento relativo en el costo de la cuenta.
La serie AI Impact regresa a San Francisco – 5 de agosto
La siguiente etapa de inteligencia artificial aquí: ¿estás listo? Únase a los líderes de Block, GSK y SAP para analizar exclusivos sobre cómo reiniciar a los agentes independientes de las tareas de flujo de trabajo de la Fundación, desde las decisiones en un momento real para la automatización integral.
Asegurar su lugar ahora: el espacio es limitado: https://bit.ly/3gulf
Esto lo hace perfectamente adecuado para tareas de inferencia de alto rendimiento, investigando el pensamiento complejo o proporcionando la precisión del nivel de límites a los bajos gastos de tiempo de funcionamiento. En Cogito V2, el modelo MEE 671B actúa como pionero, y se beneficia de su eficiencia y eficiencia en la dirección de que coincida o pase por alto los principales modelos abiertos en los estándares, con el uso de cadenas de pensamiento más cortas significativamente.
Los modelos ahora están disponibles Bordado Para descargar y usar por empresas y en No es vulnerable al uso localO para aquellos que no pueden organizar las conclusiones del modelo en sus propios dispositivos, a través de las interfaces de la API (API) de Juntos, Amnistía Internacionaly Base y Runbod.
También hay una cantidad8 bits de punto flotante (FP8)«Una versión de 671B, que reduce el volumen de números utilizados para representar los parámetros del modelo de 16 bits a 8 bits, ayuda a los usuarios a ejecutar modelos enormes más rápido, más barato, más barato y más fácil de acceder, especialmente con los requisitos para los requisitos casi no casi (lo que se menciona en él es el caso.
Los cuatro modelos Cogito V2 están diseñados como sistemas de pensamiento híbrido: pueden responder inmediatamente para preguntar, o cuando sea necesario, reflexionan internamente antes de responder.
Es muy importante que esta reflexión no sea solo el momento de la operación, se hornea en el proceso de capacitación en sí.
Estos modelos están entrenados para absorber su pensamiento. Esto significa que los mismos caminos que toman para alcanzar respuestas (pasos mentales, si está permitido hablar, se destilan nuevamente en los pesos de los modelos.
Con el tiempo, aprenden cualquier línea de pensamiento ya importante y cuál no.
El blog Deep Cogito, «Investigadores», también nota la forma de «Moster serpenteante» para poder alcanzar la respuesta y, en cambio, desarrolla una intuición más fuerte para la ruta de investigación correcta para el proceso de pensamiento. «
El resultado, como Cogito profundo, es un rendimiento mejorado más rápido, más eficiente y general, incluso en la situación «estándar» que se les llama.
Estimulación de autointeligencia
Mientras que muchos en la comunidad de inteligencia artificial solo enfrentan la compañía, Deep Cogito se basa en silencio durante más de un año.
Salió del fantasma en abril de 2025 con una serie de modelos de código abierto entrenados en el meta de Llama’s Llama. Estas versiones tempranas mostraron resultados prometedores.
como VentureBeat Anteriormente se informó que el Cogito V1 más pequeño (3B y 8B) superó a las homólogos de Lama 3 a través de varios criterios, a veces con amplios márgenes.
El CEO y cofundador de Deep Cogito, Drishaan Arora-A, ex ingeniero de LLM en Google, el objetivo a largo plazo de la compañía a largo plazo, ya que la construcción de modelos que pueden mejorar con cada repetición, como cómo mejorar Alfagu a través de los tintos.
Reemplaza el método básico de cogito profundo, destilación refinada y amplificación (IDA), reclamos escritos a mano o estables con visiones avanzadas del modelo.
¿Qué es la «intuición»?
Con Cogito V2, el equipo tomó este episodio mucho más. La idea central es simple: pensar no debe ser solo una herramienta para el momento del razonamiento; Debería ser parte de la inteligencia básica del modelo.
Por lo tanto, la compañía aplicó un sistema en el que el modelo ejecuta cadenas de pensamiento durante la capacitación, luego está capacitado en sus ideas intermedias.
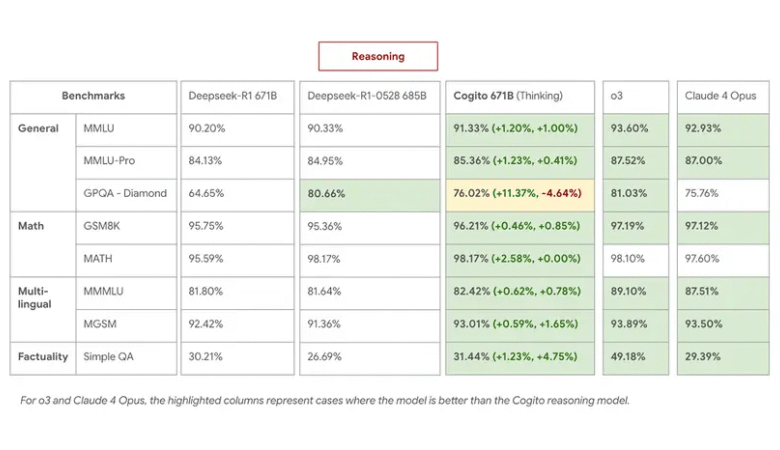
Este proceso ofrece mejoras concretas, de acuerdo con los estándares internos. El modelo MEE 671B MEE supera a Deepseek R1 en tareas de pensamiento, coincidiendo o superando el último 0528 con el uso de cadenas de pensamiento más cortas en un 60 %.
En MMLU, GSM8K y MGSM, Cogito 671B MEE fue igual a los mejores modelos abiertos como Qwen1.5-72b y Deepseek V3, y se acercó al nivel de rendimiento de modelos cerrados como Claude 4 Opus y O3.
especialmente:
- Cogito 671B MEE (Modo de pensamiento) Depsek R1 0528 a través de tareas de control de control y conocimiento general de lenguaje múltiple, y lo supera en estrategia y descuento lógico.
- En el modo no estacional, Deepseek V3 0324 excedió, lo que indica que la intuición destilada conlleva un peso real de rendimiento incluso sin el curso del pensamiento extendido.
- La capacidad del modelo para completar el pensamiento de menos pasos también fueron los efectos del curso del río: bajos costos de inferencia y tiempos de respuesta más rápidos en reclamos complejos.
Arora explica esto como una diferencia entre buscar una ruta a cambio de saber dónde se encuentra el destino.
«Dado que los modelos de Cogito desarrollan una mejor intuición para el camino que debe tomarse mientras buscan en el momento del razonamiento, tienen cadenas de pensamiento 60 % más cortas que Deepseek R1». Sobre un tema sobre x.
¿Cuáles son los tipos de tareas que superan los nuevos modelos de cogito profundos al usar la intuición de su dispositivo?
Algunos de los ejemplos más persuasivos de la prueba interna de Cogito V2 son exactamente cómo aparece esto en uso.
En un reclamo de matemáticas pesadas, el usuario pregunta si el tren que viaja a 80 millas por hora puede llegar a una ciudad 240 millas en menos de 2.5 horas.
Mientras que muchos modelos imitan la cuenta paso a paso y a veces cometen los errores de conversión de la unidad, Cogito 671b refleja internamente, determina que 240 ÷ 80 = 3 horas, y se concluye correctamente que el tren es No es posible Llega a tiempo. Solo lo está haciendo con un corto pensamiento interior, a 100 íconos, comparados con más de 200 utilizados por Deepseek R1 para alcanzar la misma respuesta.
En otro ejemplo que incluye el pensamiento legal, el usuario pregunta si el fallo de la Corte Suprema de los Estados Unidos se aplicará a un problema virtual que incluye investigaciones e incautaciones. La posición de pensamiento en Cogito resalta la lógica de dos pasos: DirTO determina si el valor predeterminado coincide con un precedente y luego explica el motivo o no. El modelo alcanza una respuesta precisa con una clara justificación: un tipo de pensamiento interpretativo de que muchos LLM todavía están luchando.
Otras tareas muestran mejoras en el tratamiento del misterio. En una pregunta clásica de varios derecho: «Si ella no es la madre de Bob, y Bob es el padre de Charlie, ¿qué no es para Charlie?» Los modelos a menudo se entrelazan en los pronombres. Los modelos Cogito V2 introducen correctamente a Alice como la abuela de Charlie, incluso en los cambios que están ligeramente formulados a medida que otros modelos abiertos tropiezan.
Amplia eficiencia
A pesar del gran tamaño de los nuevos modelos, Deep Cogito afirma que entrenó los ocho modelos de Cogito, incluido el punto de control V1 más pequeño $ 100 millones más Para algunos modelos líderes en OpenAi.
Esto incluye la generación de datos, la mejora sintética, la infraestructura y más de 1,000 experiencias de capacitación. En comparación con los nueve presupuestos de números para otros modelos fronterizos, son parte del gasto típico.
Arora atribuye este activo a la tesis básica de la compañía: los modelos más inteligentes necesitan mejores dispositivos de control, no más símbolos.
Al enseñar al modelo a superar los caminos de pensamiento excesivos o engañosos, Cogito V2 proporciona un rendimiento más fuerte sin el tiempo de reciclaje.
Este es un trueque significativo para los usuarios que operan modelos en infraestructura o dispositivos API donde se encuentran el comino y los costos.
¿Cuál es el siguiente para Deep Cogito y V2?
La versión Cogito V2 no es un producto final, pero es un paso repetitivo. Arora describe la hoja de ruta de la compañía como «escalada en la colina»: modelos continuos, aprendiendo de los efectos del pensamiento, la destilación y la repetición del episodio. Con el tiempo, cada estilo se convierte en una piedra para moverse por otro.
Cada modelo DEP Cogito es de código abierto, y la compañía dice que esto seguirá siendo correcto para futuras repeticiones.
De hecho, su trabajo atrajo la atención y el apoyo de partidarios como Eric Vishria de Benchmark y South Park Commons Agarwal.
Abrazando la cara, Togetter AI, Runpod, Baseten, Meta’s Llama Team y Uph.
Para los desarrolladores, investigadores e equipos de instituciones, ahora están disponibles modelos. Los desarrolladores pueden operar localmente, comparar situaciones o deshacerse de los casos de uso especificados.
Para la comunidad de inteligencia artificial más amplia, Cogito V2 ofrece más que solo un nuevo ganador, sugiere una forma diferente de construir inteligencia. No pensando mucho, sino aprendiendo a pensar mejor.

Enlace de origen



